안녕하세요, 매우 오랜만에 공부 섹션에서 인사드립니다.
얼마전에 살짝 시간이 비어 웹서핑을 하다가 재밌는 주제를 발견했습니다.
바로, '성시경 vs. 장범준, 누가 더 나은가?' 라는 논란이었습니다.
상당히 격렬한 댓글이 오고가서 많이 놀랐는데요, (전 개인적으로 성시경 팬입니다만)
비록 제 전문분야는 아니지만, 언젠가 Naver에서 출시한 CLOVA Sentiment API에 관해 들은적이 있어서 이를 활용해보면 재밌지 않을까 싶어 글을 올려봅니다.
(활용법은 https://www.ncloud.com/product/aiService/clovaSentiment 이곳을 참고하시기 바랍니다.)
네이버에서 어떠한 알고리즘으로 api를 만들었는지는 참고자료가 없어서 reference를 첨부하지 못하는 점 유감스럽게 생각합니다.
아래 분석에 대한 상세한 코드가 궁금하신 분들은 이곳 을 참고 부탁드립니다.(주의: 코드가 매우 지저분할 수 있습니다ㅠ)
그럼 시작합니다!
주의! 그냥 재미를 위한 분석이니 분석 결과에 큰 의미를 두지 말아주시기 바랍니다.
-----
1. 데이터 프로세싱
1 a) 댓글을 싹 가져옵니다.
* 모든 커뮤니티 사이트를 돌지는 못하고, 가장 댓글이 많은 한곳을 정해 댓글을 가져왔습니다. 약 4000여개의 댓글을 가져왔습니다.

1 b) 두 가수들에 대한 키워드를 포함한 댓글을 추출합니다.
* 두 가수들과 관련없는 댓글들을 제외시키기 위함입니다. 이름, 별명, 히트곡 등을 키워드로 정했습니다. 약 2000여개를 추출했습니다.
* 성시경 키워드 = ["시경", "성식", "거리에서", "두사람", "희재], 장범준 키워드 = ["범준", "버스커", "벚꽃", "여수", "노래방에서"]
1 c) 한 ID당 하나의 댓글만을 남깁니다.
* 처음엔 이 스텝을 그냥 넘어갈까 하다가, 아래의 충격적인 결과를 봐서 중복 ID 제거를 결정했습니다.
* 그 어떤 옹호나 비하의도 절대없고, 중복 ID 제거에 대한 이유를 설명하기 위한 목적의 수치만을 기록한 것입니다.
* 이런 현상이 sentiment score에 영향을 주는것을 방지하기 위해 한 ID당 하나의 댓글(첫댓글)만을 남겼습니다.
1 d) 데이터를 성시경, 장범준 관련 데이터로 split 합니다.
* Sentiment analysis API 는 sentiment를 문장별로 측정합니다. 예를들어,
"성시경 좋아요" "장범준 좋아요" --> 이 두개 모두 positive sentiment score를 가집니다. 이것들이 한 데이터셋에 있다면 각 가수별 score를 측정하기가 어렵습니다.
따라서 데이터를 가수별로 분리해서 각각의 positive, negative sentiment를 구하기로 했습니다.
* 위에서 사용한 키워드들을 이용해 분리하였습니다. 성시경과 장범준 둘 모두의 키워드를 포함한 댓글들은 제외했습니다. 왜냐하면 이럴경우 해당 문장의 sentiment score가 누굴 위한 것인지 구분하기 힘들기 때문입니다.
* 여기서부터는 코드는 첨부하지 않겠습니다. (제 실력부족으로 코드가 너무 깁니다 ㅠ)
2. Sentiment analysis
* 네이버 CLOVA Sentiment를 이용해 sung_df, jang_df 각 데이터셋의 sentiment를 측정합니다.
* 여기서는 두가지 방식으로 sentiment score를 도출했습니다.
2 a) comment-by-comment
* 가장 직관적인 방법으로, 각 댓글을 API로 넘겨서 댓글별 sentiment를 산출하는 방법입니다.
* 네이버 API는 call 한번에 1000자까지 처리 가능하고, 가격은 call당 1원씩 부과됩니다 (월 1000회 무료). 따라서, 두 가수들의 댓글을 모두 처리하는데에 약 500회의 call을 하게 됩니다.
* 구해진 sentiment를 바탕으로 점수를 구해봤습니다. 단순 positive 점수만 비교하면 장범준이 많이 앞섭니다. 이는 장범준을 극찬한 문장들이 많거나, 성시경을 미지근하게 칭찬하는 문장들이 많았어서일까요?
* 좀 더 그럴듯한 비교를 위해, positive와 negative score를 합산한 후, 그 중 positive의 비중을 구하였습니다
sent_score = (positive / (positive + negative)) * 100.

* 장범준이 positive, negative 두 쪽에서 모두 확연하게 큰 것을 알 수 있습니다. 이 중 positive의 비중을 계산하면, comment-by-comment 방법상에선 성시경이 앞서게 됩니다.
2 b) merging comments into documents
* 두번째 방법은 댓글들을 합쳐서 약 1000자 이내의 document로 만들어서 계산하는 방법입니다. 이렇게 하면 API를 call 하는 횟수가 확연히 줄어들고, 그만큼 처리속도도 빨라집니다.
* CLOVA Sentiment는 merge된 comment를 document로 받아서 API 내에 지정된 stop words를 이용해 다시 문장으로 끊습니다. (?, !, . 같은 부호나 "~하네", "~하다" 등 뭔가 문장을 마칠때 쓰는 글자를 이용). 이후 각 sentence의 sentiment를 측정하는 것으로 보입니다.
* 따라서 이 방법으로는 각 댓글별로는 score를 알기 힘들고, API가 임의로 끊은 sentence별로 score 측정이 가능합니다. 이 방법으로는 call 수가 약 ~40회로, 첫번째 방법의 1/10 정도도 되지 않습니다.
* 이 방법을 이용해 도출한 결과는 다음과 같습니다.

* 첫번째 방식과 상반되는 결과를 얻었습니다. merging 방법상으로는 장범준이 앞서게 됩니다.
* 이렇게 차이가 나는 원인은, 댓글간의 길이 차이를 고려하는지 여부입니다. 첫번째 방법에서는 댓글별로 score를 계산하여 각 댓글이 길이에 상관없이 점수를 받습니다. 하지만 두번째 방법에서는 API가 임의로 문장을 나누다보니 한 댓글이 여러 문장으로 나뉠경우 double counting이 되는 경우가 생깁니다.
* 이 글에서는 댓글들에 동일한 비중을 주는것을 채택하고 있으므로, comment-by-comment 방식에 따른 결과를 최종 결과로 선택합니다.
* 따라서, 이 분석의 결론은 '해당 게시판에선 성시경에 대한 평가가 장범준보다 더 긍정적이다' 라고 내릴 수 있습니다.
* CLOVA Sentiment를 써보니 두 경우 모두에서 문장의 context는 감을 잘 못잡는 듯 했습니다. 예를들어 비속어가 들어가면 context 상관없이 일단 negative로 기우는 것 같았습니다. 그 외에도 문장 내의 부정적인 표현을 보고 문맥을 잘못 이해해서 문맥은 칭찬인데 negative score가 높게 측정된 문장들이 많았습니다. (예시들 참고)
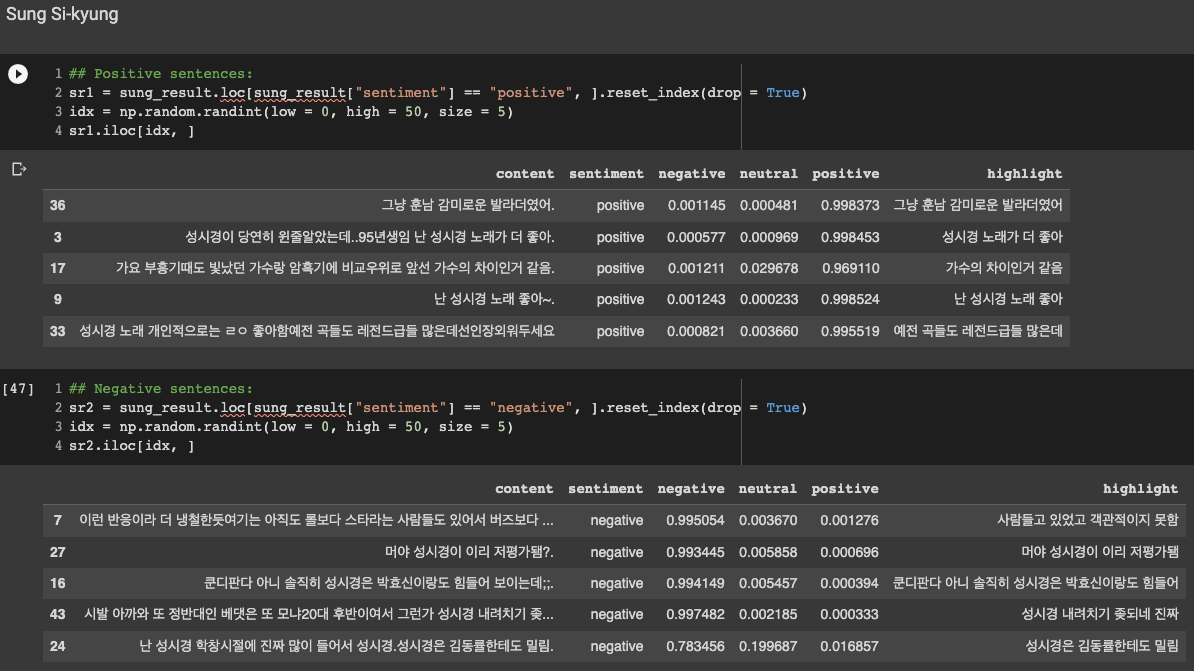
* 아래는 API에 의해 positive 및 negative로 분류된 문장들의 예시입니다. 여기서 'highlight'는 API가 score를 측정하는데에 주로 참고한 부분을 나타내는 것 같습니다.

3. Word cloud
* 내친김에 성시경, 장범준 관련 word cloud도 만들어보았습니다. split한 데이터셋 각각에서 가장 많이 쓰인 단어 top 50개를 뽑아 나타내봤습니다.

제 전문분야가 아니다보니 뭔가 이론적인 백그라운드는 전혀 제공하지 못해서 쑥쓰럽습니다. 그냥 여가시간에 잠깐 해본 toy project이니 너그러이 봐주시면 감사하겠습니다.
다시한번 말씀드립니다만, 이 분석은 네이버의 API를 활용해 재미로 해본것이니 지나친 비난은 삼가 부탁드립니다.
그 외 궁금증이나 피드백은 언제든 환영입니다!
다음에도 재미있는 주제를 들고 돌아오겠습니다. 감사합니다!
'캐나다 대학원 > 공부' 카테고리의 다른 글
| [2022.08.20] M2 맥북에어에 R + VS code 환경 세팅하기 (0) | 2022.08.21 |
|---|---|
| [RL] 3. Value Functions (0) | 2020.07.07 |
| [RL] 2. Multi-Armed Bandits Problem (0) | 2020.07.03 |
| [RL] 1. Reinforcement Learning Overview & Terminology (0) | 2020.07.02 |
| VSCode + WSL+ Python 환경을 세팅하다 (부제: 개삽질) (2) | 2020.06.29 |